Table of Contents
AI21 Labs’ Summarize API Outperforms OpenAI’s Models in Human Evaluation

The ever-growing amount of online content makes it difficult for individuals and businesses to remain informed and make informed decisions.
Summarize API, one of our new Task-Specific APIs, is specifically built to tackle this textual overload in documents, articles, websites and more, by condensing lengthy amounts of text into short, easy-to-read bites.
Summarize API is powered by an optimized language model trained to perform summarization tasks, as opposed to general Large Language Models (LLMs) such as Open AI’s GPT family, which do not target any one specific task.
So which model is better at summarizing?
Methodology
We evaluated AI21 Labs’ Summarize API performance against OpenAI’s Davinci-003 and GPT-3.5-Turbo models, using various types of prompts, across both academic and real-world datasets (GPT-4 is not yet available for comparison at the time of writing this post).
We measured performance using both automated metrics and human evaluation.
Automated metrics include:
- Faithfulness rate – an indication of whether a summary is faithful, i.e., factually consistent with the original text
- Compression rate –the length of the generated summary relative to the original
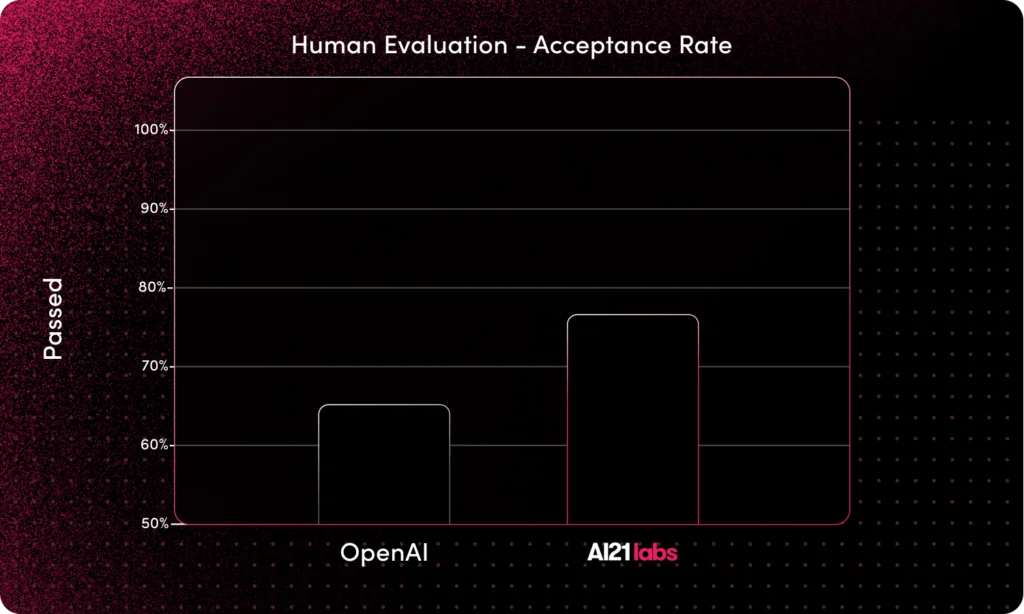
Human professionals conducted blind evaluations in a methodological process measuring pass rate – the rate of summaries acceptable in real-world use cases.
Results
Across the various evaluations we conducted, AI21 Labs’ Summarize API performes better or on par with OpenAI’s models, showing higher faithfulness, compression, and pass rates.
Summarize API especially excels in tests that use real-world data, producing summaries with significantly lower levels of hallucinations and reasoning violations.
OpenAI models were 2-4x more likely to produce summaries flagged by humans as “Very Bad”, defined as completely unreliable summaries that contradict the source text or deviate from it substantially. Even with extensive prompt engineering, OpenAI’s results showed no significant improvements.
Some noteworthy stats:
- Summarize API has an 18% higher pass rate than OpenAI’s Davinci-003, even when a detailed prompt was used.
- Summarize API presents a 19% higher faithfulness score in comparison to OpenAI’s Davinci-003.
- Summarize API achieved a 27% higher compression rate than GPT-3.5-Turbo.
- Summarize API has at least a 50% lower standard deviation of compression rate, meaning that summaries are consistent in their short length.
Takeaways
AI21 Labs’ Summarize API outperforms or on par with OpenAI’s LLM results across a variety of models, datasets and prompt types.
The Summarize API holds other advantages as well. As an off-the-shelf solution that does not require prompting, it can generate summaries with only the original text as input. This provides a better user experience and more consistency in results.
Notably, human evaluation found OpenAI summaries to contain higher rates of hallucinations, reasoning violations and incoherence – common and costly limitations in LLMs that produce unacceptable results in real-world usage.
To learn more about the research and results, read the full whitepaper here.


