Table of Contents

Long Context, But Actually

Updated on Oct 8, 2024
Our latest and most advanced foundation models, Jamba 1.5 Large and Jamba 1.5 Mini, both offer a context window of 256K tokens, 32 times longer than the 8K context window of our previous series of LLMs, and much longer than those of similar-sized competing models.
When it comes to building language models, we’re not alone in focusing on context length. Anthropic jumped from 100K to 200K with the release of Claude 2.1, and Google from 32K to purported 2M with Gemini 1.5. But these numbers – including ours – must be analyzed carefully. Here are three questions we asked ourselves as we built Jamba-Instruct:
- Does having a long context window mean the model actually does something useful with it?
- Can you serve long context models with acceptable latency and unit economics?
- In these RAGish days, does long context matter as much?
I discuss each of these below.
A new standard for measuring long context
The mere fact that a model doesn’t choke on a long context doesn’t mean that it does something useful with it. As is the general case with evaluating LLMs, evaluating whether it does or does not do something useful is not straightforward. The common needle-in-the-haystack (NIAH) benchmark, where the model is prompted to retrieve a hidden information bit from a very long prompt, captures something of value, but doesn’t really tell you much about real-world applications.
The recent release by our friends at NVIDIA of a new benchmark, RULER, is a welcome contribution in this regard. It evaluates long context models on four categories of complex and multi-step reasoning tasks (retrieval, multi-hop tracing, aggregation, and question answering), coming much closer to capturing real-world applications.
In addition to being more comprehensive, the benchmark’s other significant contribution is to establish a “passing grade”, allowing us to distinguish between the claimed length and what they call “effective length”, the latter being defined as the maximum window length in which the model achieves a score of at least 85% on RULER.
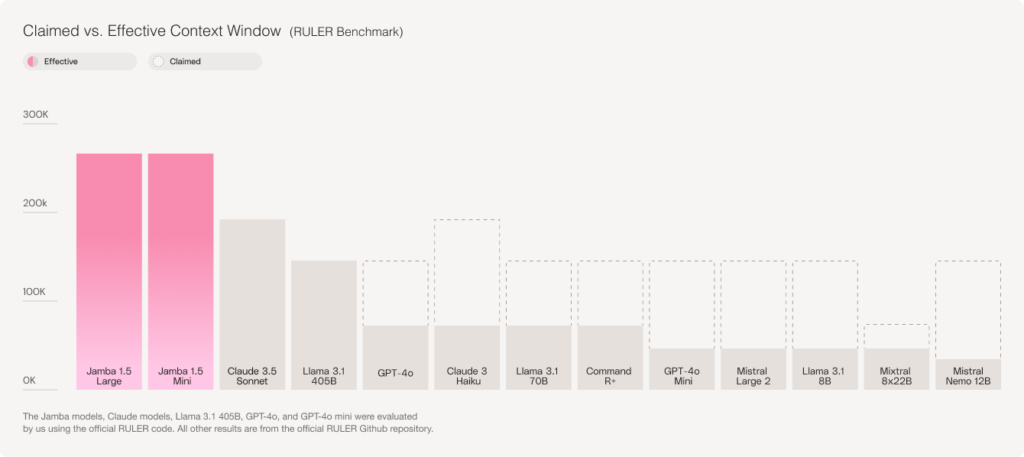
The table above shows the gaps between claimed and effective context lengths of various models. We applaud all model builders in which the two coincide. Jamba belongs in this “truth in advertising” honor list, offering the longest effective context window available on the market.
To get the full picture, here is the complete overview with the various context lengths at which the different models pass based on RULER benchmark criteria of 85% pass rate.
Why don’t claimed and effective context length always match?
An underlying reason for the discrepancy between claimed and effective context lengths is the ways in which model builders coaxed the model into accepting long contexts. The memory footprint of the Transformer architecture forces solutions such as sparse attention or sliding windows (and many others), in order to utilize longer and longer contexts. The side effect of these tricks is to compromise answer quality.
We took a different approach when building Jamba. The release of the novel Mamba architecture in December 2023 by researchers at Carnegie Mellon and Princeton Universities, offered the possibility to scale to a theoretically unlimited context window. Our team leapt at the opportunity, releasing the world’s first production-grade, Mamba-based model just several months later. And to compensate for the limitation of the SSM architecture, it added a few transformer layers. This was described in detail in our whitepaper.
Keeping latency, serving costs and memory requirements under control
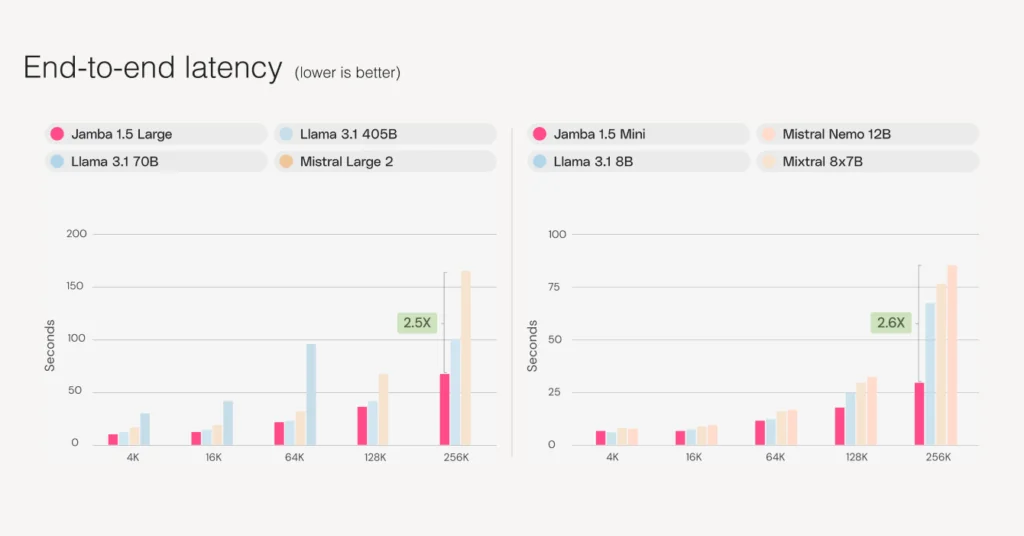
Even if you somehow ensure that the model outputs high-quality answers, if it takes it too long and costs a lot of money to produce that answer, that model is not useful.
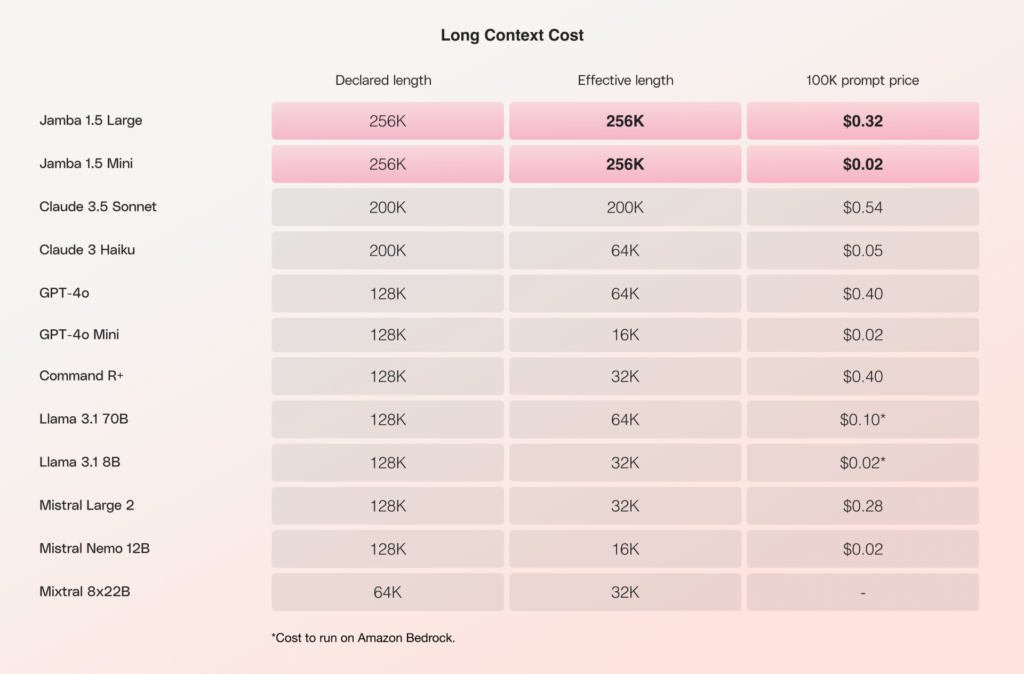
Here is a chart that also incorporates the current costs of the models evaluated above.
And here is a graph that compares the Jamba 1.5 models with other open models in their size class on performance.
Both Jamba models also show excellent speed and throughput results in independent tests run by Artificial Analysis, as can be seen in the chart below; at context lengths of 10K, Jamba 1.5 Mini ranks as the fastest model.
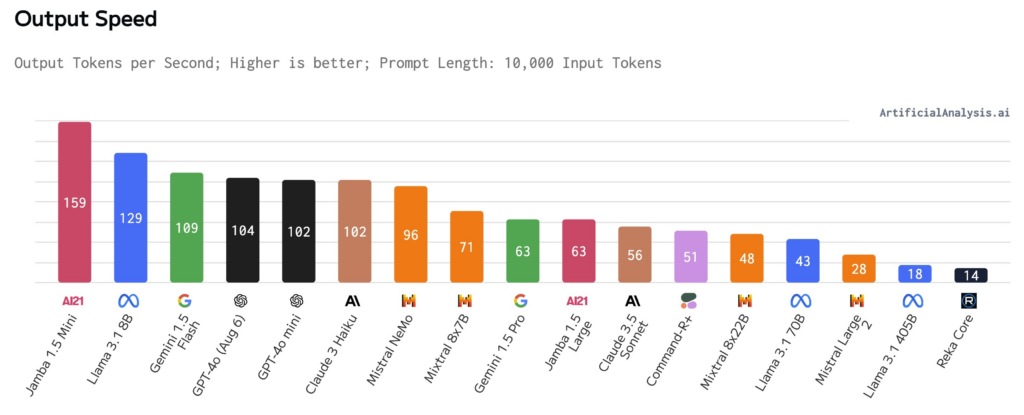
The almost linear complexity of Jamba’s hybrid SSM-Transformer architecture enables it to achieve this excellent cost efficiency and performance, maintaining the Transformer’s impressive quality without suffering the complexity of a pure transformer design.
Perhaps the best way to visualize the effective context window versus the serving costs of the model is the following chart.
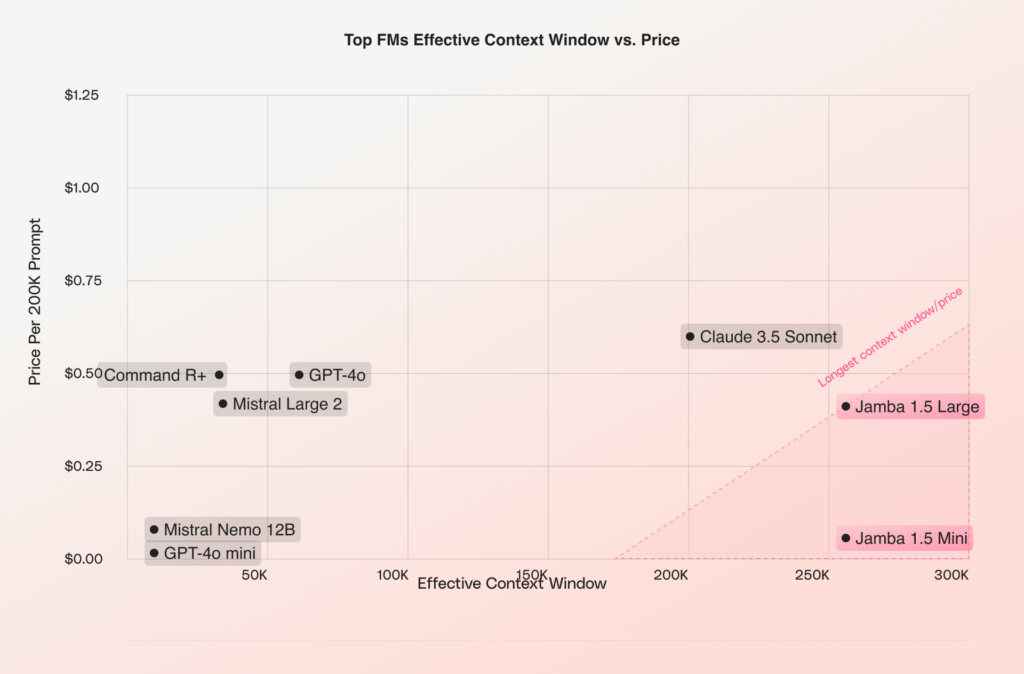
The chart speaks for itself. Both Jamba models offer the longest context window at a fraction of the cost of the few others that feature a comparable length.
It’s long context and RAG, not either/or
One sometimes hears arguments that RAG obviates the need for long context – retrieve just the information, and you don’t need the long context. But that’s not the case; rather, the two reinforce each other. In building an AI system that pairs the two, the long context model improves the quality of RAG’s retrieval stage, and RAG provides the blueprint for scaling this high-quality long context processing.
The benefits of this long context + RAG future shows up everywhere in enterprise applications, from advanced search to information synthesis and beyond. For example:
Customer support: A company could use Jamba-Instruct and AI21’s RAG Engine to build a question answering tool for their customer support agents. With Jamba-Instruct’s 256K context window, the RAG Engine will be able to retrieve more snippets from across millions of knowledge base documents, producing an answer that is consistent with its context and more accurate.
Financial document summarization: An investment firm could build a summarization tool for its analysts, enabling the RAG Engine to retrieve full documents instead of stranded chunks from the firm’s internal database of records and reports, and generating more reliable and accurate summaries of key points as a result.
These are just examples of how companies can begin thinking about how long context can strengthen RAG pipelines, with long context models enhancing the retrieval stage to produce more reliable output and RAG serving to scale this process.
Just as we built the novel Jamba architecture by leveraging the advantages of both Mamba and Transformer architectures, so, too, we believe the best and most powerful AI systems will be built by leveraging the advantages of multiple components to create a highly-specialized system, customized for each client.
If you’re interested in building and scaling GenAI workflows that leverage long context and RAG, let’s talk.


