In a Nutshell
In recent work described by an ICLR 2021 spotlight paper, we show how to replace BERT’s random input masking strategy during pretraining with PMI-Masking, which jointly masks neighboring tokens if they exhibit high correlation over the pretraining corpus. By preventing the model from focusing on shallow local signals, PMI-Masking achieves better representations at a fraction of the training budget. Despite altering only the input masking strategy, PMI-Masking achieves the same BERT pretraining quality in one sixth the time and achieves significantly better pretraining within the same training budget.
Masking: BERT’s Added Degree of Freedom
Before BERT, neural Language Models (LMs) tended to be autoregressive, learning to predict each input token given preceding text. The Masked Language Model (MLM) training objective of BERT, for which the model learns to predict a masked subset of the input tokens, creates an inherently bidirectional representation of text. But this bidirectionality comes with an added degree of freedom relative to classical autoregressive LMs: choosing which tokens to mask and which to show.
Our paper highlights that not all bidirectional dependencies are equal: we show that the strategy for choosing which tokens to mask and which to show can profoundly impact an MLM’s performance. Specifically, we show that the standard practice of random uniform masking often allows an MLM to minimize its training objective by latching onto shallow local signals, leading to pretraining inefficiency and suboptimal downstream performance. By limiting the model’s ability to rely on such shortcuts, we obtain the same pretraining performance more quickly and better performance within a fixed training budget.
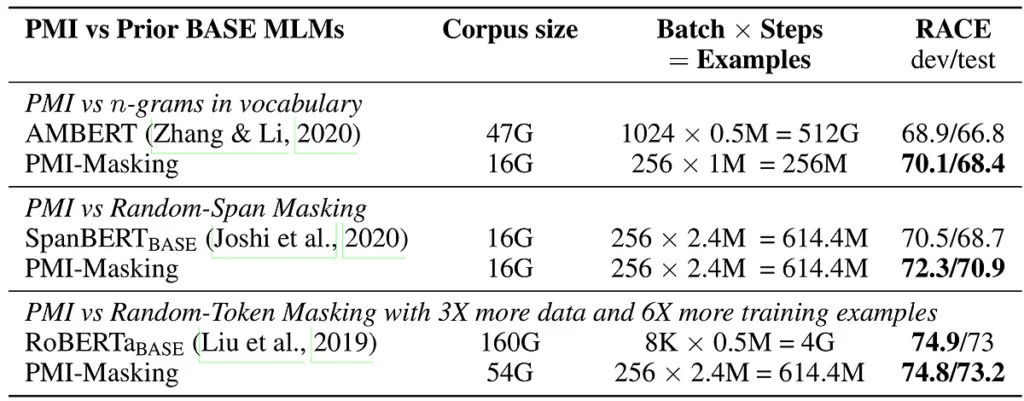
PMI-Masking speed-up and improvement relatively to existing approaches on RACE.
A Motivating Example
To see the potential harm of local signals, we offer a simple, motivating example of neighboring tokens that are highly correlated with each other: part-of-word tokens that make up the same word. Recall that BERT represents text as a sequence of tokens, where each token is either a word or a part-of-word; e.g., “chair” might constitute a single token while rarer words like “eigenvalue” do not make it into BERT’s vocabulary and are broken up into several part-of-word tokens (“e-igen-val-ue”).
When using BERT’s regular vocabulary size of 30K tokens, the vast majority of encountered words are represented by single tokens (words are represented via ~1.1 tokens on average). However, when we artificially decrease the vocabulary size to 10K and then to 2K tokens, along the x axis of the following plot, part-of-word tokens become much more common (up to ~2 tokens-per-word on average).
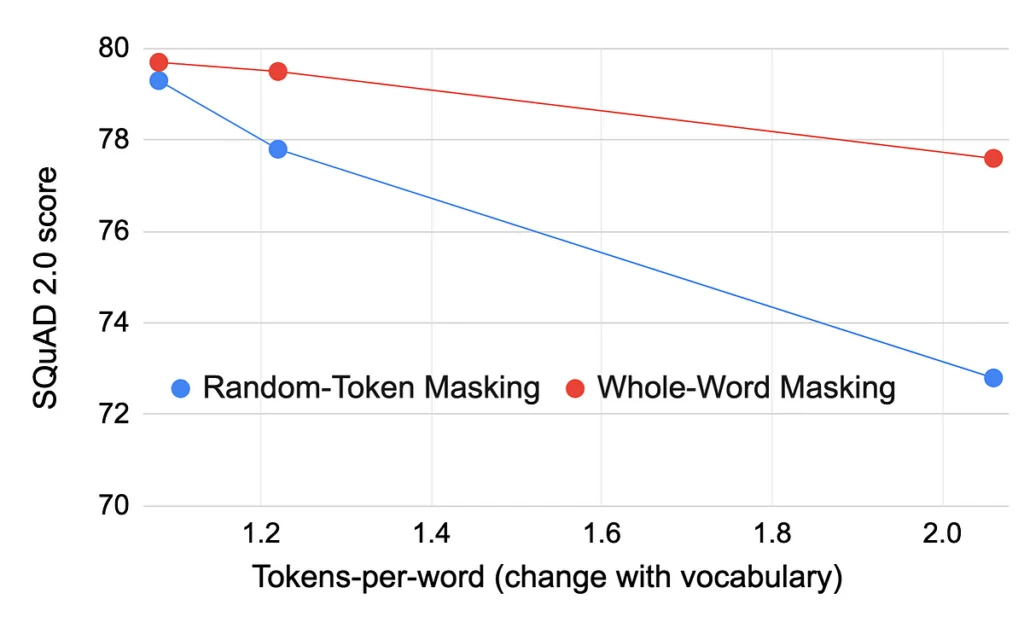
The blue curve in the above figure shows that when applying BERT’s strategy of choosing 15% of the tokens for masking uniformly at random, the model’s performance is severely degraded as part-of-word tokens become prevalent. Thus, by controlling the number of highly correlated tokens, we demonstrate that strong dependencies between neighboring input tokens can harm the model’s ability to learn from broader context. In the presence of such dependencies, the MLM’s objective can often be minimized simply by considering immediate neighbors of the masked token (consider the easy task “e-igen-[mask]-ue”).
The red curve in the above figure shows that the degradation is substantially attenuated when local cues are occluded. This is done by applying whole word masking, a popular masking strategy which jointly occludes all part-of-word tokens comprising a word. Our PMI-Masking strategy, presented below, extends this solution to a much more prevalent class of highly correlated tokens: correlated word n-grams.
Correlated Word N-Grams
The above example of part-of-word tokens illustrated a flaw in BERT’s vanilla random masking approach, and the same issue occurs for correlated word n-grams, a class of correlated tokens that is harder to identify but affects any word level vocabulary. Examples include phrases and multi-word expressions such as “editor in chief”, “at once”, “carbon footprint”, and so on. More broadly, many words provide a hint regarding the identity of their neighbors, and such shallow cues can be used by the model to minimize its objective while putting less emphasis on broader context.
Previous work has proposed masking strategies that can mitigate the effect of such local cues. Notably, Sun et al. (2019) proposed Knowledge Masking, which jointly masks tokens comprising entities and phrases, as identified by external parsers. The restriction to specific types of correlated n-grams, along with the reliance on imperfect tools for their identification, has limited the gains of this approach. With a similar motivation in mind, SpanBERT of Joshi et al. (2020) introduced Random-Span Masking, which masks word spans of lengths sampled from a geometric distribution at random positions in the text. Random-Span Masking was shown to consistently outperform Knowledge Masking, however, with high probability the selected spans break up correlated n-grams, such that the prediction task can often be performed by relying on local cues.
We offer a principled approach to masking spans that consistently provide high signal, unifying the intuitions behind the above approaches while also outperforming them. In order to identify highly correlated word n-grams, we rely on the measure of Pointwise Mutual Information (PMI), which quantifies how surprising a bigram w1w2 is, given the unigram probabilities of w1 and w2 in the corpus. Formally, given two tokens w1 and w2, the PMI of the bigram w1w2 is:
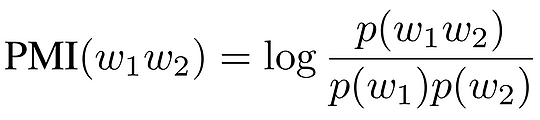
Where the probability of an n-gram p(w1… wn) is computed by the number of its occurrences in the corpus divided by the number of all n-grams in the corpus.
PMI is a good indicator of correlation between words comprising a bigram, but extending it to measure correlation between words comprising longer n-grams is nontrivial. We propose the following extension of PMI to longer n-grams, and show that it provides a better signal than existing alternatives:
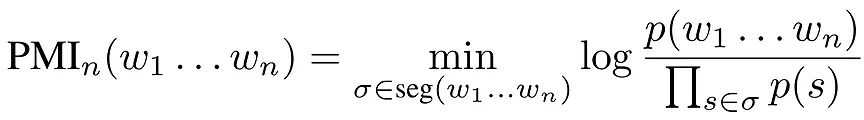
where seg(w1… wn) is the set of all contiguous segmentations of the n-gram w1… wn (excluding the identity segmentation), and where any segmentation σ ∈ seg(w1… wn) is composed of sub-spans that together give w1… wn.
Intuitively, this measure discards the contribution of high PMI subsegments of the considered n-gram; the minimum in the equation above implies that an n-gram’s score is given by its weakest link, i.e., by the segmentation that comes closest to separability. This way, trigrams such as “Kuala Lumpur is” are deranked, since despite the bigram “Kuala Lumpur” having high PMI it is not highly correlated with the word “is”, whereas “editor in chief”, which cannot be broken to uncorrelated subsegments, is promoted for joint masking.
Experiments
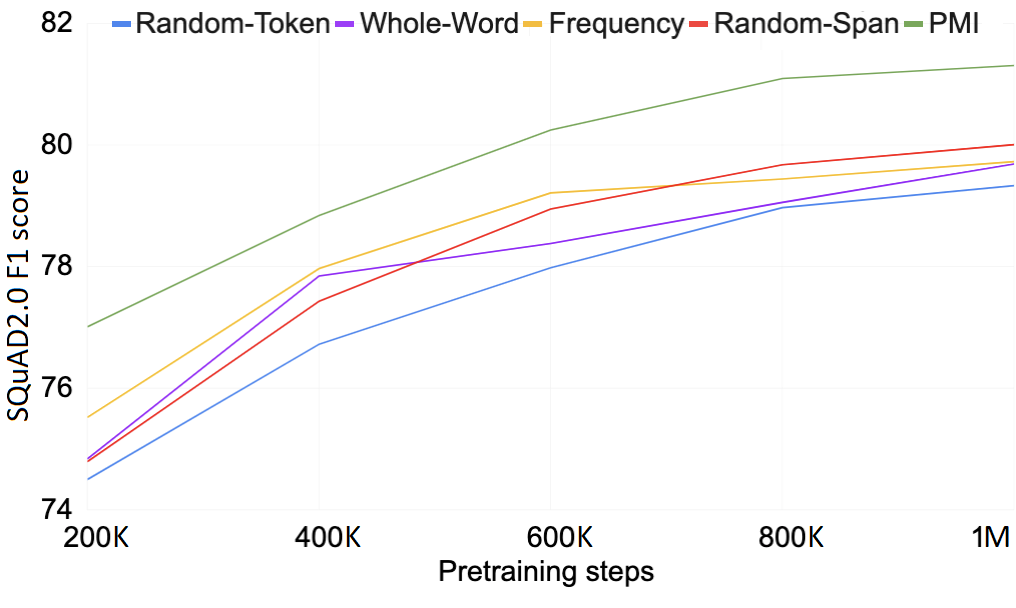
By jointly masking n-grams with high PMIn scores, we speed up and improve BERT’s pretraining. When training models with either BERT’s vanilla random-token masking, SpanBERT’s random-span masking or PMI-Masking, in BERT’s original training setup (see details in paper), we get the following 1 to 2 point advantage in prominent benchmarks:
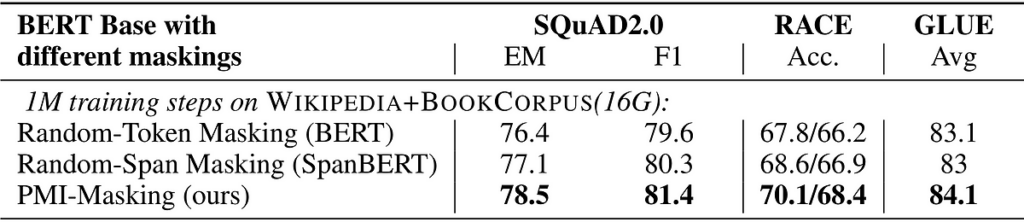
When comparing to prominent released models of the same size (see table at the top of this post), we see that:
- PMI-Masking outperforms a parallel approach of integrating word n-grams as tokens (PMI-Masking vs. AMBERT).
- PMI-Masking retains its advantage over random-span masking when training continues for 2.4 times longer than BERT’s original training (PMI-Masking vs. SpanBERT).
- PMI-Masking reaches the performance attained by vanilla random-token masking after ⅙ of the training time (PMI-Masking vs. RoBERTa).
1 Sun et al. (2019): “ERNIE: Enhanced representation through knowledge integration”
2 Joshi et al. (2020): “Spanbert: Improving pre-training by representing and predicting spans”
3 We acknowledge useful comments and assistance from our colleagues at AI21 Labs