We designed a simple and efficient method, called Auxiliary Tuning, for adapting a pre-trained Language Model (LM) to a novel task, and demonstrated the approach on the task of conditional text generation.
What we did
We designed a simple and efficient method, called Auxiliary Tuning, for adapting a pre-trained Language Model (LM) to a novel task, and demonstrated the approach on the task of conditional text generation. Our approach supplements the original pre-trained model with an auxiliary model that shifts the output distribution according to the target task.
Why it matters
Achieving state-of-the-art fluency in language tasks such as text generation entails costly training of large LMs. Auxiliary Tuning allows practitioners to amortize this cost across target tasks by leveraging existing pre-trained LMs. This is done without modifying the pre-trained weights, avoiding the risks of rigidity and catastrophic forgetting, and allowing natural scaling to multiple target tasks.
How it works
The auxiliary model is trained by adding its logits to the pre-trained model logits and maximizing the likelihood of the target task output. Our method imposes no constraints on the auxiliary architecture. In particular, the auxiliary model can ingest additional input relevant to the target task, independently from the pre-trained model’s input. Furthermore, mixing the models at the logits level provides a natural probabilistic interpretation of the method.
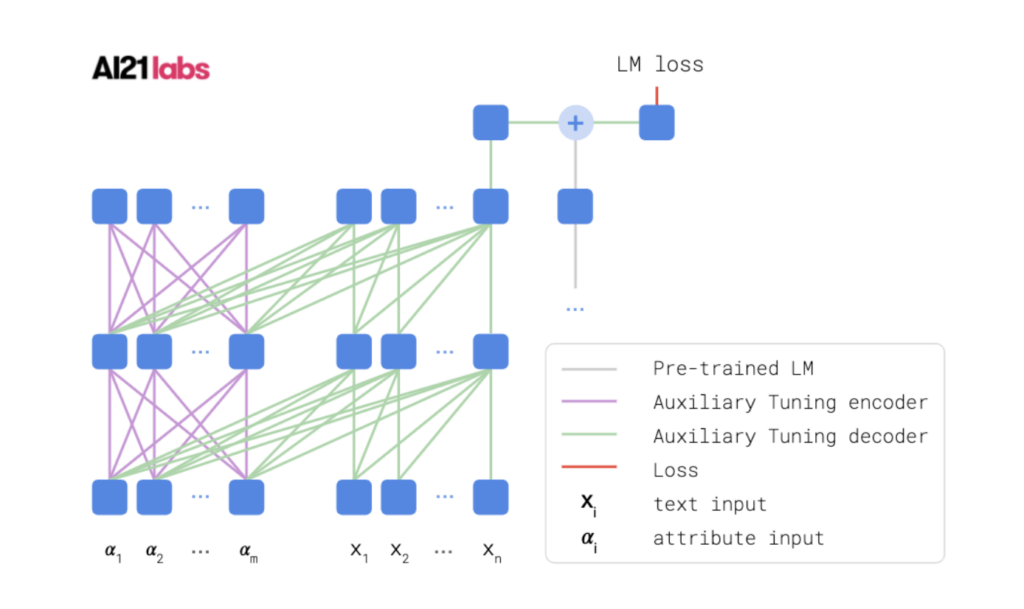
Results
We tested Auxiliary Tuning on a number of different conditional text generation tasks. Adapting a pre-trained LM using our method resulted in similar performance to training a comparable model on the target task from scratch, while using significantly less compute for training. Below we present results for a text generation task conditioned on keywords, where the generated text has to include the keyword provided to the model. We show that our method achieves similar accuracy (the fraction of samples that contain the keyword that we conditioned on) compared to a naive autoregressive Transformers baseline. Interestingly, our method generates fluent samples early in training, demonstrating its effectiveness of harnessing the fluency of the pre-trained model (as measured by SLOR).
Related methods
Auxiliary Tuning is related to, but different from, fine-tuning, few-shot learning, Plug-and-Play Language Model (PPLM) and side-tuning. For details, see the technical report.
Yoel Zeldes, Dan Padnos, Or Sharir and Barak Peleg