Table of Contents
The Complete Guide to LLM Product Development

The current buzz around generative AI is overwhelming. The potential it holds is exciting, promising to revolutionize industries and redefine user experiences. However, successful implementation of generative AI requires a strategic approach, an understanding of the process, and a clear roadmap to navigate the complexities involved.
At AI21 Labs, we’ve developed Large Language Model (LLM) solutions for top enterprises like Ubisoft, Clarivate and Carrefour. Our custom development process generates predictable results and revenues for our clients (to learn more about this, feel free to contact us).
Let’s break down this process into its basic stages, which require meticulous planning, precise execution, and vigilant monitoring.
1. Preparation: Plan your LLM development project
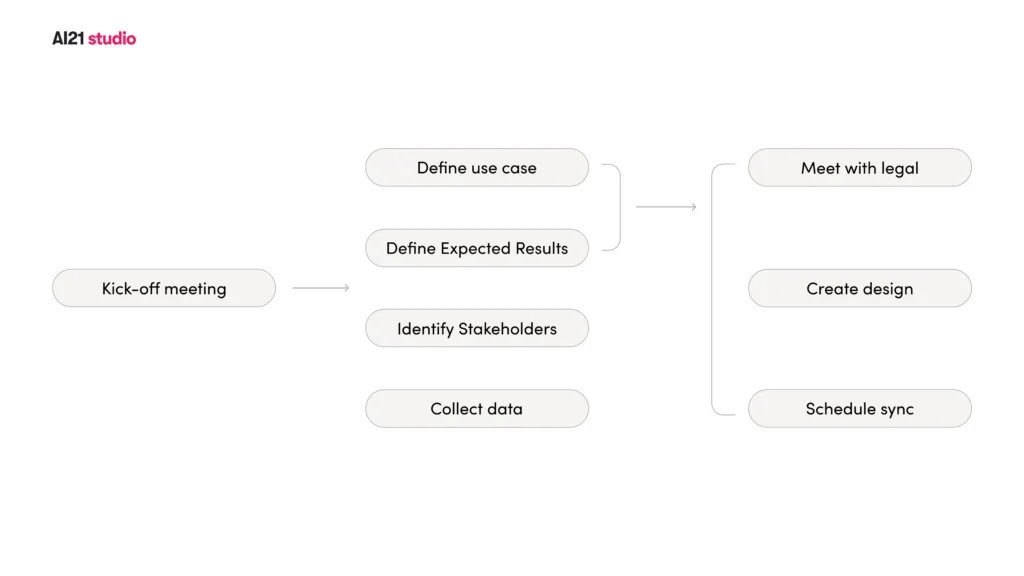
Like any successful project, an LLM development project needs to be thoroughly thought through, and well planned. The preparation stage is dedicated to mapping out the project’s overarching objectives and outlining the details of the strategic plan.
The goal of this stage
This phase can either be undertaken independently, by the company wanting to build the product, or in collaboration with the LLM provider it decides to work with.
During this stage of the process, it is important to collect the necessary resources, including the relevant data which will be used as context input, or as a dataset for an LLM training process. Some data may not be accessible to third party vendors, such as the LLM provider. It is therefore crucial to overcome these limitations at this stage.
For example, let’s take an ecommerce company that wants to create a tool that generates product descriptions for their website, based on a short list of product features. At this stage of the process, they should collect data such as a content style guide and a list of characteristics of each of their products and already existing product descriptions, which will be used as context input and output for the LLM during the training process. If, for instance, the company is unable to share some of this information with a third party vendor, perhaps because they are coming out with a new product whose details are still confidential, they should consider this issue at this stage, and seek a reasonable solution.
Identifying stakeholders
Stakeholders include strategic decision makers such as CEOs, CTOs and product managers. A product manager is usually a key player in this strategic phase, since they are well versed in both technical and business aspects.
Additionally, the people who will ultimately implement the solution must also be involved, in order to contribute their technical and practical expertise. These include data scientists, data engineers, software engineers, devops, and designers.
Furthermore, the legal and compliance team should be involved to address privacy concerns, in addition to business analysts and domain experts to assist in making the most informed strategic decisions.
2. Building the product
Once the preparation stage has been finalized, and the required results have been mapped out, it is time to build the model.
The goal of this stage
During this stage, the company’s goal is to implement all of the plans made in the preparation stage, to reach the desired outcome; namely, for the LLM model to accept a certain input and retrieve an appropriate output.
Tasks to be completed at this stage
1. Choosing a language model: This will be done with the help of the LLM provider. There are a number of different factors to consider based on the specific use case. These factors include cost, performance and the model’s ability to handle the use case complexity.
2. Defining the user flow and wireframes: This phase entails outlining the user’s interface with the tool being built, alongside determining the anticipated user-input data, its format, and the desired output. This step, if done correctly, will save a lot of time when developing and building your product.
3. Data Curation: This involves curating and preparing the necessary data for the specific use case. This can include examples of different types of inputs that the various components of the LLM will be provided with, as well as examples of desired outputs. This data will be used to test the model’s outputs at the model evaluation stage. If data security issues have not been solved yet, this is the time to determine which data can be shared, and find solutions to any data privacy issues.
4. Training / Prompt Engineering: This is a crucial task in which the company customizes the Language Model to fit their specific needs.
This can be done using one of two methods, or a combination of both.
The first is to further train the language model by feeding it examples of inputs and expected outputs. This allows us to learn the intricacies of specific language patterns. The second is prompt engineering. This involves crafting well-defined input queries, instructions, or context for a language model to provide accurate and relevant responses, optimizing its expected outputs for specific tasks or applications.
5. Model Adjustments (Parameters): Adjust the parameters to optimize response quality according to your specific needs. This step refines the model’s ability to understand and produce human-like responses, aligned with your product’s objectives. Read more about parameters here.
6. Model Evaluation: Assess your model’s performance against a diverse set of scenarios and benchmarks. This evaluation provides insights into its strengths, weaknesses, and areas for improvement, ultimately guiding you towards a polished end product.
7. Pre-processing and Post-processing: Pre-processing involves cleaning and structuring input data for the model, while post-processing polishes the model’s output, ensuring it’s coherent, grammatically sound, and aligned with your brand’s needs.
Structuring Prompts for Scalable Product Descriptions with LLMs
Referring back to our example of an ecommerce company developing a product description generator, at this stage, they must determine which language model to use. In this particular case, a foundation model would be most appropriate.
When aiming for automated, high-quality product descriptions, the structuring of your input prompt is pivotal. By thoughtfully designing this prompt, businesses can generate countless descriptions that are not only unique to each product but also consistently adhere to the brand’s tone, style, and guidelines.
Here’s the breakdown of the ideal three-part input structure:
- Brand Guidelines (Constant): This section forms the backbone of every product description. By embedding your brand guidelines into the prompt, you ensure that each generated description remains faithful to your brand’s voice, tone, and values. For instance, the guidelines might instruct the LLM to maintain a certain tone (e.g., technical, precise), emphasize specific details, or follow a particular format.

- Product Details (Variable): This is the dynamic section of the prompt, tailored for each product. By substituting placeholders such as {Product Name} and/or {List of Features}, businesses can automate the description generation for a vast array of products.

- Instruction (Constant): A consistent directive informs the LLM about the exact task, such as creating a one-paragraph product description. This ensures the output meets the desired format and adheres to the brand guidelines every single time.

The advantage of this modular prompt structure is its scalability. Once an organization has established its brand guidelines and instruction segments, it can easily slot in different product details to churn out descriptions in bulk. The constant sections (1 and 3) ensure brand consistency, while the variable section (2) ensures product specificity. This systematic approach provides a streamlined solution, ensuring both efficiency and quality in product description generation.
And here’s an example of what we would expect from the product description:

Pro tip: Although many companies wish to create a completely automated system, it is important to have a human monitoring the system to ensure quality output.
3. Model deployment
Once satisfied with the model’s demonstrated proficiency and effectiveness in producing desired outcomes, the next step involves the strategic deployment of the model onto the platform of choice.
The goal of this stage
This step marks the transition from theoretical concept to real-world utility, enabling the integration of the model’s capabilities into the intended environment. The overarching goal is to have the model working on the desired platform, so that the end user can utilize it.
Referring back to our product description generator example, at this stage, the company will integrate the product description generator into their internal systems. This will make it accessible to the people tasked with creating product descriptions.
Tasks to be completed at this stage
Deploying an LLM onto the desired platform involves a streamlined process which can be done through a number of different methods: connecting the model directly through an API, utilizing an SDK, or leveraging a cloud server. AI21 Labs models are available through Amazon SageMaker, Amazon Bedrock, and Google Cloud Platform. This makes the models easily accessible to any company using any of those providers.
By integrating with the LLM provider’s API, you establish a direct communication channel between your platform and the model. This enables seamless transmission of input queries and retrieval of model-generated responses. Additionally, leveraging a cloud server, such as those offered by major cloud providers, allows you to host the LLM and make it accessible over the internet. This cloud-based deployment ensures scalability, enabling your platform to handle varying workloads efficiently.
Pro tip: Ensure that your final product undergoes a complete quality assurance (QA) and testing process before launch.
4. Monitoring results
The final stage of this process is to monitor the released product and analyze its performance.
The goal of this stage
The main aim is to keep a close eye on the product’s technical performance as well as what impact it’s having on the business.
The goal is to understand how users are reacting, how much they’re engaging with the product, and receive and analyze their feedback. This is also the time to improve, expand, or grow the product. If the results aren’t as expected, this is the time to examine what is and isn’t working, and act accordingly.
At this stage, the ecommerce company, as discussed in our example, should start using the generator to create product descriptions. It should also monitor results. This includes observing how users are reacting to the updated product descriptions and whether they are seeing an increase, decrease or no change in their sales.
Further improvements
To ensure the optimal performance of a product, maintaining a consistent line of communication with the LLM vendor is imperative. This ensures the seamless integration of any new models and capabilities post-product launch. In addition, it is critical to conduct periodic tests, so that any issues can be addressed promptly. In the event of any problems, early communication with the LLM vendor is of paramount importance. This facilitates timely diagnosis of the problem’s root cause and the development of a feasible solution. Such proactive engagement with the LLM vendor aligns with the philosophy of continuous improvement and ensures that the product consistently meets its intended standards.
Conclusion
In the dynamic landscape of modern business, LLM-based solutions have surged in significance. However crafting an LLM-driven product requires nuanced understanding and meticulous planning. This journey encompasses careful preparation, precise model construction, strategic deployment, and vigilant monitoring. As the LLM-based product evolves, continuous learning and adaptation remain essential.
To learn more about LLM product development, contact our team at AI21 Studio.


