

Trusted by developers in leading companies






Why AI21 Studio?
Foundation Models
Take on any language task. Our Jurassic-2 models are trained to follow natural language instructions, requiring no examples to adapt to new tasks.
Build with Jurassic-2Task-Specific Models
Use our specialized models for common tasks like contextual answers, summarization, paraphrasing and more. Access superior results at a lower cost without reinventing the wheel.
Build with Task-Specific ModelsCustomizable
Need to fine-tune your own custom model? You're just 3 clicks away. Training is fast, affordable and trained models are deployed immediately.
Our technology partners




Embed AI-first experiences in your product
Leverage AI21 Studio's API across industries and use-cases
AI co-writer
Give your users superpowers by embedding an AI co-writer in your app. Drive user engagement and success with features like long-form draft generation, paraphrasing, repurposing and custom auto-complete.
AI co-reader
Help your users combat information overload. Compress long documents into short summaries, extract key points and offer high-fidelity semantic search over knowledge bases.
AI business insights
Make sense of unstructured text sitting idly in your data lake. Solve topic classification, sentiment analysis, entity extraction and other challenging language understanding tasks in 15 minutes.
AI content automation
Automate repetitive tasks across all stages of the writing process: drafting, editing and review. Empower content teams to easily expand their reach to new markets, platforms and audiences.
Built for developers
Get up and running with one API call.
Start building for free, no credit card required.

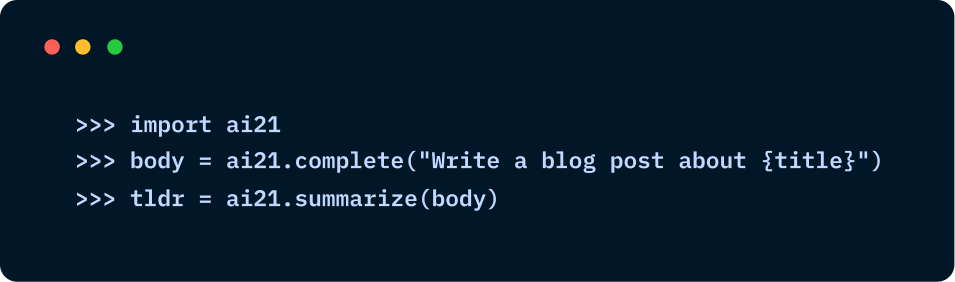
Integrate your favorite stack with just three lines of code
Compress timelines and reach your roadmap goals faster with our enterprise-ready API
Built for scale
We support millions of end users, and we know traffic can fluctuate with seasonality and business needs. Bring it on.
99.99% uptime
Enterprises need production grade reliability.
Designed for security
We are ISO27001 compliant.
Dedicated support
Our NLP experts are here to support you every step of the way.
Hear it from our customers
״We were looking for language models that are fast and reliable while staying cost-effective. AI21 Studio offers all of that in addition to being agile which is a must in our fast-paced marketplace!״
״AI21 Studio was a game changer in powering our chatbots. We experienced an immediate impact both from our users and from the quality of information we extracted from chats with our users. Our conversion rate improved by 10X within a few weeks!"
Playground
Interact with the models, explore our presets and play around. Ready to take things to the next level? Our API is at your disposal.
Documentation
Learn more about our language models, read the API reference, discover guides and best practices.
Community
Join the conversation in our Discord server. Regular updates, questions and feature requests - we are here to listen.
Here for you
Want to rely on our models, but need some extra guidance? Our NLP experts are happy to help and answer any questions.
Our mission is to revolutionize reading and writing. Our applications Wordtune and Wordtune Read already help millions of users every day. We’re here to help you do the same for your users!